
 Een misverstand wat ik regelmatig terug hoor komen in relatie tot SEO, is dat het uitsluiten van (een deel van) je website met het Robots.txt bestand ervoor zorgt dat je uit de index van Google en andere zoekmachines blijft.
Een misverstand wat ik regelmatig terug hoor komen in relatie tot SEO, is dat het uitsluiten van (een deel van) je website met het Robots.txt bestand ervoor zorgt dat je uit de index van Google en andere zoekmachines blijft.
Maar dat is onjuist! Dat is ook logisch. En ik zal uitleggen waarom.
Case: Auping.nl
Laat ik dit verduidelijken met een voorbeeld. Aanbieder van bedden Auping.nl heeft had de gehele website uitgesloten van het ‘crawlen’ door zoekmachines middels het Robots.txt bestand (uitleg).
Bewust of niet, Auping geeft zoekmachines geen toestemming om de website te laten crawlen (lees voor meer uitleg over crawlen “Hoe werkt een crawler-based zoekmachine?“).
SEO misverstand
Google en andere zoekmachines kijken in het proces van crawlen het eerste naar het Robots.txt bestand. En de (Disallow) commando’s in het Robots.txt bestand worden gehoorzaamd.
In het geval van Auping stopt de zoekmachine crawler dus zodra deze bij Auping.nl of 1 van de onderliggende pagina’s aankomt.
Robots.txt uitsluiting, toch in index?
Een SEO misverstand is dat dit tot gevolg heeft dat de website van (in dit geval) Auping.nl niet in de index van zoekmachines terecht komt.
Dat is onjuist.
Zoals je ziet, is Auping.nl namelijk gewoon te vinden in Google:
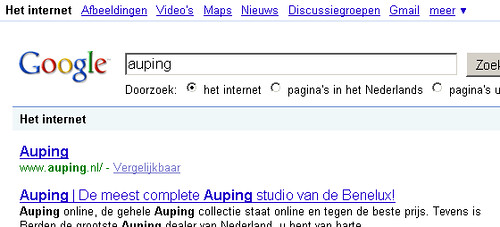
En dat is logisch.
Gebruikerservaring zoekmachines
Zoekmachines willen namelijk een goede zoekervaring bieden. En als je zoekt op Auping, zou het imago van Google en andere zoekmachines geschaad worden als auping.nl niet op positie 1 staat.
Dat is de reden dat websites of webpagina’s toch in de index van Google en andere zoekmachines terechtkomen als ze zijn uitgesloten middels Robots.txt.
Crawlen geblokkeerd, hoe toch in index?
Een zoekmachine stopt in het geval van Auping.nl direct met crawlen bij het bereiken van de website. Maar hoe weten zoekmachines dan dat de Auping.nl website bestaat?
Simpel. Vanwege inkomende links van andere websites.
Een website of webpagina hoeft dus maar 1 inkomende link te hebben van een ander domein – wat zoekmachines wel mogen crawlen – en zoekmachines weten van het bestaan van de URL af.
Zoekresultaat samenstellen
En op basis van bijvoorbeeld de linktekst (anchor tekst) kunnen zoekmachines er een passende titel aan geven. En niet verassend is ‘auping’ de meest voorkomende anchor tekst:
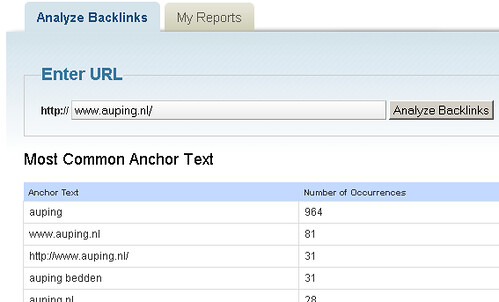
Zoals je hierboven zag, heeft het zoekresultaat van Auping geen omschrijving. Dat is logisch, omdat zoekmachines geen content of een meta description kunnen crawlen.
Als Auping was opgenomen in het Open Directory Project (DMOZ), wat niet zo is, had Google daar een omschrijving uit kunnen halen om het zoekresultaat compleet te maken.
Zo. Dat is de reden dat een website of webpagina’s, die uitgesloten zijn in het Robots.txt bestand toch in de index van Google en andere zoekmachines verschijnen.
Hoe dan wel uit index?
Hoe kun je dan wel een webpagina uitsluiten van indexatie? Gebruik daarvoor de Meta Robots tag met de waarde “noindex”.
Zorg er dan wel voor dat de betreffende webpagina niet is uitgesloten in Robots.txt. Want dan kunnen zoekmachines de Meta Robots tag nooit vinden 😉
Lees er meer over in mijn uitgebreide handleiding: “Hoe Verwijder Je Informatie Uit Google?”
Video uitleg Matt Cutts
Zie hier ook de video uitleg van Google’s ‘webspam opperhoofd’ Matt Cutts:
Ps. de reacties lijken nog steeds stuk, waarvoor excuses. Reageer gerust via Twitter of neem contact op als je het probleem wilt fixen voor me 😉

Trackbacks/Pingbacks