
In mei 2007 heeft Google ‘Universal Search’ gelanceerd. Dit is hun benaming voor het uitbreiden van de reguliere tekstresultaten met meer soorten informatie, zoals afbeeldingen en video’s. Ook wordt er informatie gegroepeerd per onderwerp toegevoegd, zoals nieuws en blogs, ook wel verticale zoekmachines genoemd.
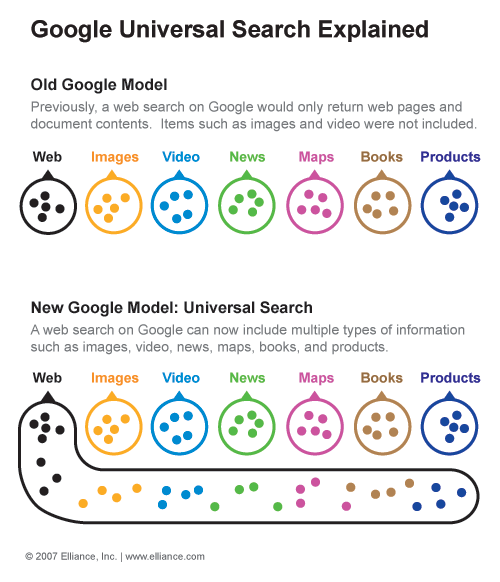
Naar mijn mening beschrijft de term ‘Blended search’ deze integratie van verschillende vormen van informatie beter. Het is in feite een logische ontwikkeling, want op deze manier kan Google jou als zoeker een nog beter antwoord geven op je zoekvraag.
Niet-Engelstalige zoekresultaten aangevuld
Van alle content die Google in haar gigantische index heeft opgeslagen, is het grootste gedeelte Engelstalig. In sommige niet-Engelstalige landen is de aanwezige content daarom simpelweg beperkt.
Om de niet-Engelstalige landen toch een rijkere zoekervaring te bieden, heeft Google vorig jaar ‘Cross Language Information Retrieval‘ (CLIR) gelanceerd (Information Retrieval is de wetenschappelijke benaming voor – het oplossen van de problematiek rond digitaal – zoeken).
De techniek maakt gebruik van hun vertaalservice Google Translate om Engelstalige zoekresultaten te vertalen naar de betreffende niet-Engelstalige taal.
Voorbeelden Google CLIR
Zoals we van Google gewend zijn, wordt dit eerst zorgvuldig en op kleine schaal getest. Maar Google lijkt de test iets uit te breiden. Zelf kwam ik het vorige week ook in Nederland tegen:
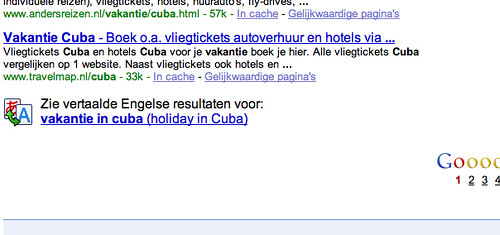
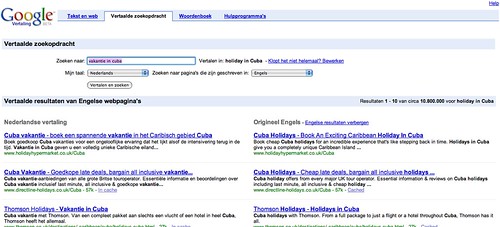
Ik kon het zoekresultaat zojuist nog steeds reproduceren. Ook Joost de Valk vond er onlangs in Duitsland een voorbeeld van.
Goed idee
Conceptueel vind ik Cross Language Information Retrieval een sterk idee. Zeker in de kleinere niet-Engelstalige taalgebieden is de content nu eenmaal beperkt.
Een aanvulling van die beperkte content met relevante content vanuit de aanzienlijk grotere hoeveelheid Engelstalige content is in mijn ogen een verrijking van de zoekervaring.
Slechte vertaling
Aan de andere kant is de vertaalservice Google Translate simpelweg niet goed. Ik vind het bijzonder opmerkelijk dat er tot op de dag van vandaag nog steeds geen goede automatische vertaalmachine bestaat. De meeste vertaalmachines gaan helaas niet veel verder dan ‘woordjes ruilen’.
Dat is denk ik ook de reden dat Cross Language Information Retrieval nog zeer beperkt wordt gebruikt. Op de manier zoals het in bovenstaande voorbeelden is geïntegreerd, lijkt me ook de enige juiste op dit moment.
Google laat de gebruiker op dit moment gelukkig de keuze of ze aangevulde vanuit het Engels vertaalde zoekresultaten willen zien. Ook tonen ze de Engelstalige en niet-Engelstalige zoekresultaten naast elkaar.
Toekomst
Alleen als de vertaalservice aanzienlijk verbetert, zie ik een toekomst voor Cross Language Information Retrieval. Uiteindelijk kunnen de vertaalde zoekresultaten dan verder in de huidige zoekresultaten worden geïntegreerd.
Uiteraard is de geografische context van de zoekopdracht hierin belangrijk. Als je zoekt naar een kapper in Amsterdam, heb je niets aan een uit het Engels vertaald zoekresultaat van een kapper uit Londen. Maar Google kennende, zullen ze dat wel voorkomen.
Ben jij deze optie al eens tegengekomen?

